SVFormer: Semi-supervised Video Transformer for Action Recognition
SVFormer: Semi-supervised Video Transformer for Action Recognition 阅读笔记
亮点:
- 提出一种新颖的数据增强策略——Tube TokenMix(TTMix)。通过利用具有在时间轴上一致性的masked tokens的mask,将视频段混合。
- 提出了一种时间扭曲增强技术——Temporal Warping Augmentation(TWAug)去掩盖视频中复杂的时间变化。这个技术使得选定的帧拉伸到视频段中不同的时间持续期间。
- 这篇论文的结果很好,尤其是在Kinetics-400数据集上比SOTA(CMPL)涨点31.5%。
背景及解决措施
在互联网上,视频逐渐取代了图片和文字,所以有了很多没有标签的数据。监督学习已经靠着标记数据取得了成功,但是标记数据太耗费时间和耗费金钱。为了利用上大规模的无标记数据,所以采用半监督学习做动作识别。
以前的SSL方法是采用图像增强如Mixup或者CutMix来加速收敛,但是这种方法只适用于图像数据,这种方法用于视频会使得网络忽视掉视频数据天然具有的时间信息。所以作者提出了TTMix这种适合Video Transformer的数据增强方法。
之前的时间增强方法,只考虑了时间的缩放或移动,忽视了在人体运动中的各个部分的时间变化。为了帮助模型学习强时间动态,所以作者提出了TWAug。这个方法是对空间增强的补充
TWAug和TTMix结合,实现了显著的效果提升。
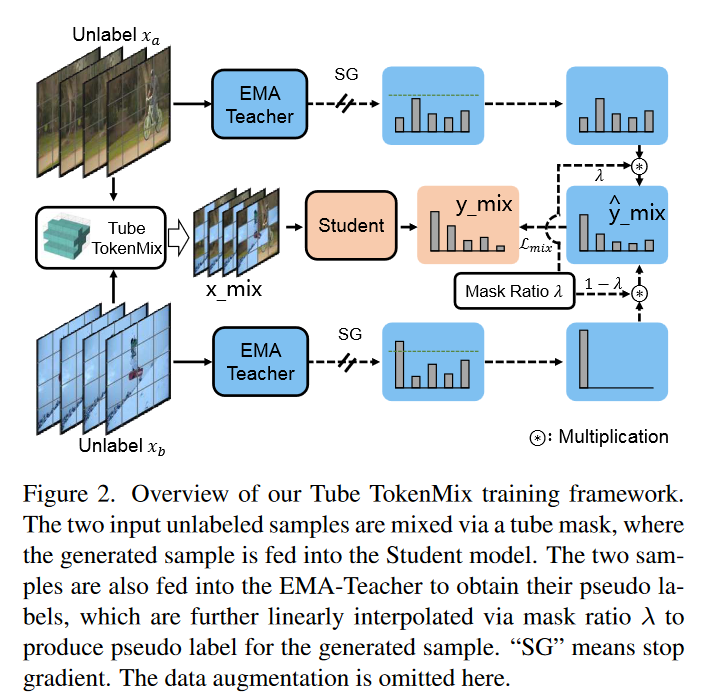
详细方法
模型的训练分成两部分:
对于有标签数据\(\{(x_l,y_l)\}^{N_l}_{l=1}\) ,这个模型优化下面的监督学习loss函数\(\mathcal{L_s}\) \[ \mathcal{L_S}=\frac{1}{N_L}\sum^{N_L}{\mathcal{H}(\mathcal{F}(x_l),y_l)} \]
其中\(x_l,y_l\) 分别指的是第\(l\) 个视频段和其对应的标签。总共有\(N_l\) 条标记视频。\(\mathcal{H}(·)\) 指的是标准交叉熵损失函数,\(\mathcal{F}(·)\) 指的是模型的预测结果。
对于无标签数据\(x_u\) ,采用弱增强(如随机水平翻转、随机缩放、随机剪裁)和强增强(如AutoAugment、Dropout)两种措施生成两种视图\(x_w = \mathcal{A_{weak}}(x_u),\ x_s = \mathcal{A_{strong}}(x_u)\)。对弱增强视图进行推理得到数据的伪标签\(\hat{y}_m = arg\ max(\mathcal{F}(x_w))\) 。生成的伪标签通过下面的loss函数用于监督强视图。 \[ \mathcal{L_{un}} = \frac{1}{N_U} \sum^{N_U}\mathbb{I}(max(\mathcal{F}(x_w)) > \delta)\mathcal{H}(\mathcal{F}(x_s),\hat{y}_w) \] 其中\(\delta\) 是置信阈值,\(\mathbb{I}\) 是指示函数,最大类概率大于\(\delta\) 时取1否则取0。这个指示函数用于过滤噪声伪标签。
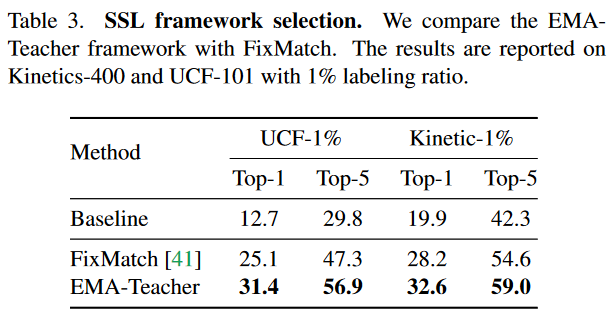
为了避免模型在训练的时候崩溃,作者采用指数移动平均(EMA)-Teacher模型在FixMatch中。参数更新公式: \[ \theta_t \gets m \theta_t + (1-m)\theta_s \] 其中\(m\)时动量系数。\(\theta_t,\theta_s\) 分别是teacher模型的参数和student模型的参数。
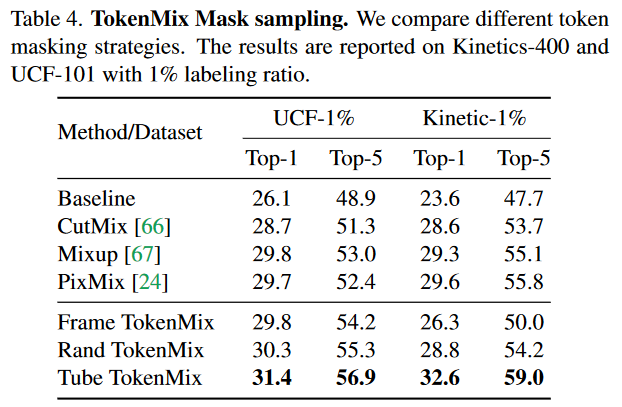
Tube TokenMix
Mixing in Videos
参考上面pipeline(pipeline中省略了数据增强的部分)。Mixing in Videos指的是\(x_a,x_b\) 经过Tube TokenMix 生成 \(x_{mix}\) 的过程。细节如下:
给了两段无标记的视频\(x_a,x_b \in \mathbb{R}^{H \times W \times T}\)
利用token级的\(M \in \{0,1\}^{H \times W \times T}\),进行样本混合。其中H,W是对视频帧进行token化之后的高和宽,T是剪辑长度。这个\(M\)就是Tube TokenMix生成的蒙版。
通过下面的式子混合\(x_a,\ x_b\)。其中\(\odot\) 指的是 element-wise multiplication,对应元素相乘即Hadamard Product(学到了高级的表达)\(\mathbf{1}\) 指的是全为1的矩阵。 \[ x_{mix} = \mathcal{A_{strong}}(x_a) \odot \mathbf{M} + \mathcal{A_{strong}}(x_b) \odot \mathbf{(1-M)} \]
然后将得到的\(x_{mix}\) 喂入student model \(\mathcal{F_s}\) 得到预测标签\(\hat y_{mix} = \mathcal{F}(x_{mix})\)
先对\(x_a,\ x_b\)进行弱增强,然后喂到Teacher model中通过如下过程产生伪标签\(\hat y_a, \ \hat{y}_b\): \[ \hat{y}_a = arg\ max(\mathcal{F_t}(\mathcal{A_{weak}}(x_a))) \\ \hat{y}_b = arg\ max(\mathcal{F_t}(\mathcal{A_{weak}}(x_b))) \] 注意如果 $max(((x))) < $ 则\(\hat y\) 就是\(\mathcal{F_t}(\mathcal{A_{weak}}(x))\) (这里对应了pipeline中的虚线。)
\(x_{mix}\)的伪标签通过下面的方程生成 \[ \hat{y}_{mix} = \lambda·\hat{y}_a + (1-\lambda)·\hat{y}_b \] 这个方程是参考Mixup方法提出的。
首先常用于生成带有高质量伪标签的数据的数据增强方法是Mixup。通过对样本-标签对进行如下的凸组合的方式生成新的数据。 \[ \hat{x} = \lambda·x_1 + (1-\lambda)·x_2, \\ \hat{y} = \lambda·y_1 + (1-\lambda)·y_2, \] 其中 \(\lambda\) 符合\(\beta\)分布。
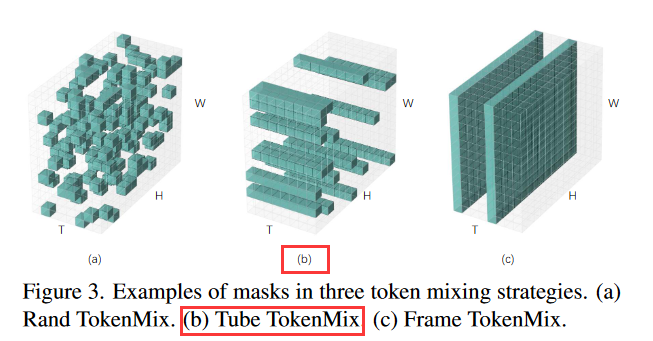

这里为了可视化,所以在图像级展示了各种混合方法的效果。
- Mixup是两幅图像像素加权融合。
- CutMix是随机剪切图像块状融合。
- PixMix是像素级的融合,像素值不是选a的帧就是选b的帧。
- FrameTokenMix是在时间轴上,从视频段a中选择帧替换掉视频段b中对应时间的帧从而形成新的视频段。
- RandTokenMix是在每个a,b对应的帧上,使用PixMix,然后在生成新的视频段上的不同帧的过程中用的mask每次都不同。
- TubeTokenMix跟RandTokenMix的区别就是,不同时间上的帧融合用的mask相同。
最后student model通过下面的一致性损失函数进行优化: \[ \mathcal{L}_{mix} = \frac{1}{N_m}\sum^{N_m}(\hat{y}_{mix} - y_{mix})^2 \] 其中\(N_m\) 是混合样本\(x_{mix}\)的数目。
对于TTMix的一致性损失算法如下:

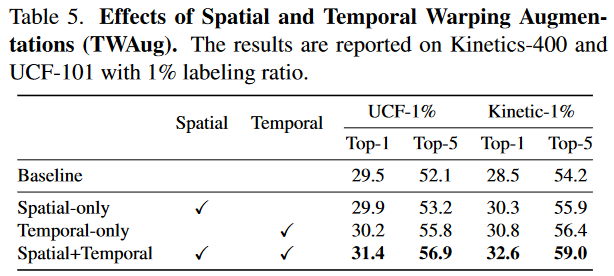
Temporal Warping Augmentation(TWAug)
这部分的作用是,能够把一帧拉伸到不同的时间长度,这样做是为了给数据引入更多的随机性。
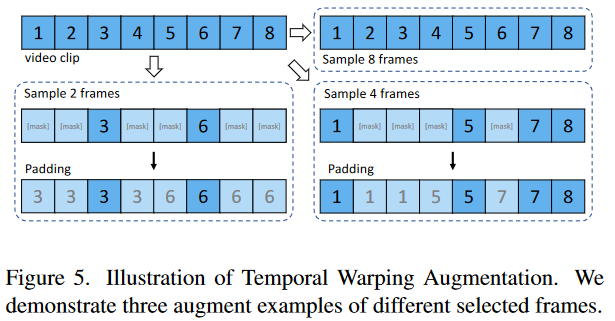
给定一个T帧的视频如上图,随机决定是保存全部的帧,或者保存小部分帧。对于保存部分帧的情况,会随机填充邻近的可见帧。作者说TWAug可以帮助模型在训练过程中学习灵活的时间动态。
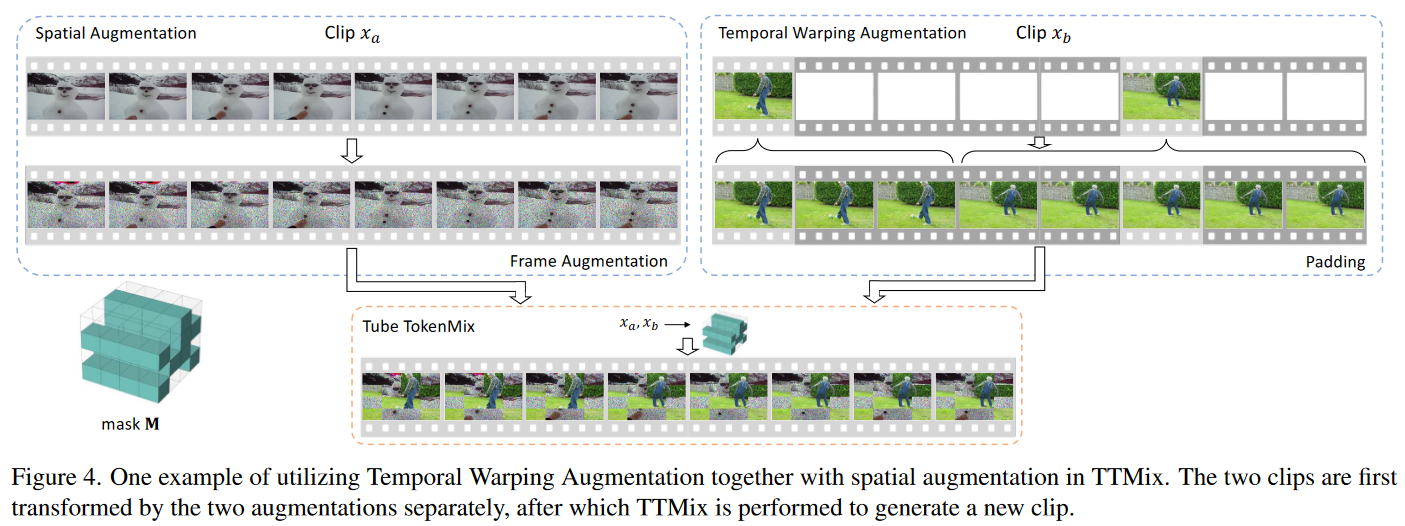
如上图所示,作者采用了常规增强(对Clip\(x_a\) 的处理)和TWAug(对Clip\(x_b\) 的处理)两种方式分别处理两个输入,然后再经过TTMix进行混合。
训练过程
训练分为三部分:
监督学习 \[ \mathcal{L_S}=\frac{1}{N_L}\sum^{N_L}{\mathcal{H}(\mathcal{F}(x_l),y_l)} \]
无监督伪标签一致性损失 \[ \mathcal{L_{un}} = \frac{1}{N_U} \sum^{N_U}\mathbb{I}(max(\mathcal{F}(x_w)) > \delta)\mathcal{H}(\mathcal{F}(x_s),\hat{y}_w) \]
TTMix一致性损失 \[ \mathcal{L}_{mix} = \frac{1}{N_m}\sum^{N_m}(\hat{y}_{mix} - y_{mix})^2 \]
最后损失函数如下: \[ \mathcal{L_{all}} = \mathcal{L_s} + \gamma_1\mathcal{L_{un}}+\gamma_2\mathcal{L_{mix}} \] 其中\(\gamma_1,\ \gamma_2\) 是用于平衡损失的超参数。
实验结果
Baseline是TimeSformer
8或16个GPU(具体型号没找到)
数据集
- Kinetics-400
- UCF-101
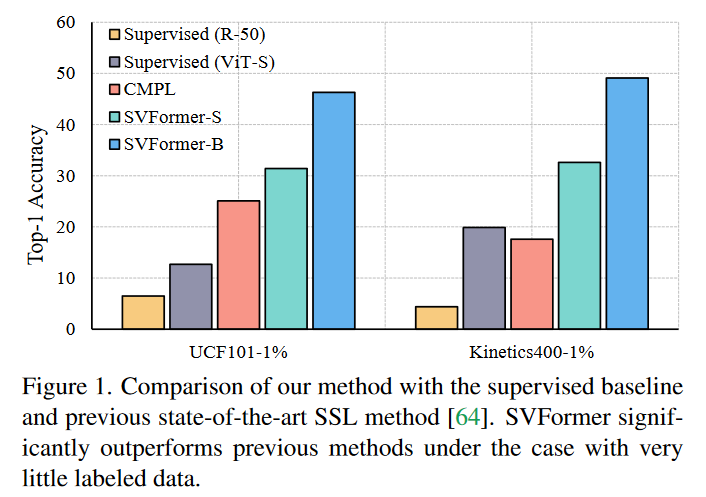
与SOTA方法比较
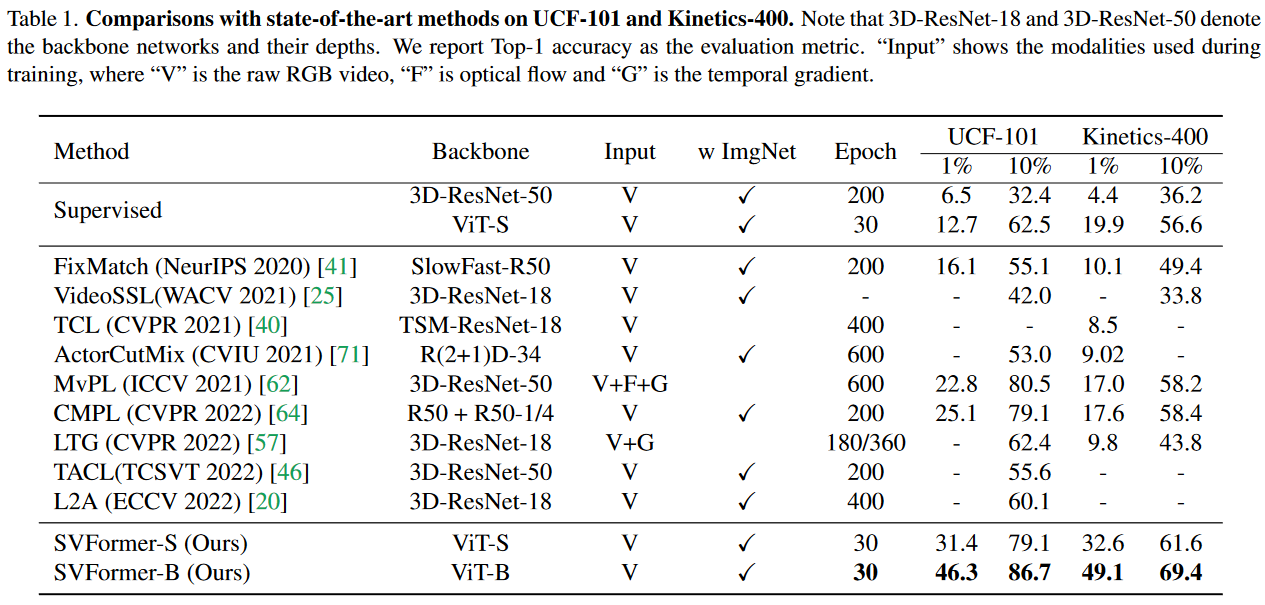
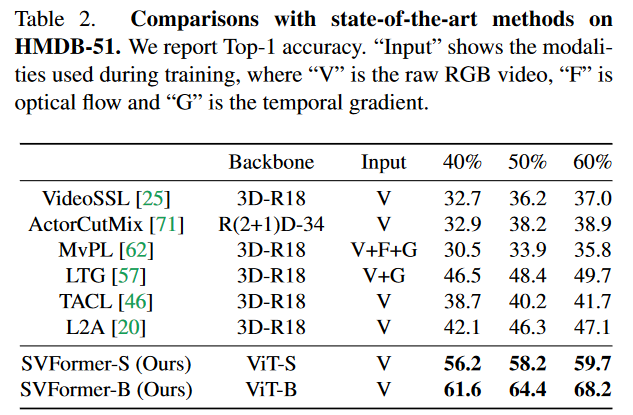
SSL 框架选择
TokenMix 效果比较
时间、空间变换增强有效性效果
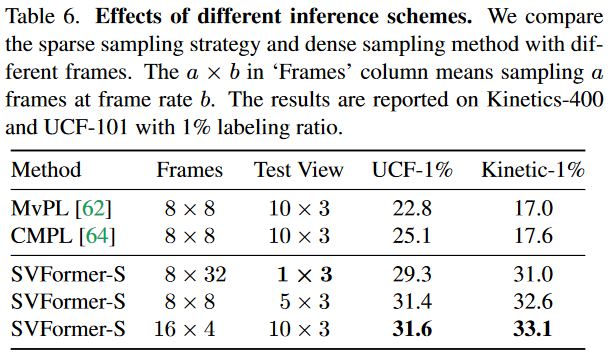
不同推理方案的有效性效果
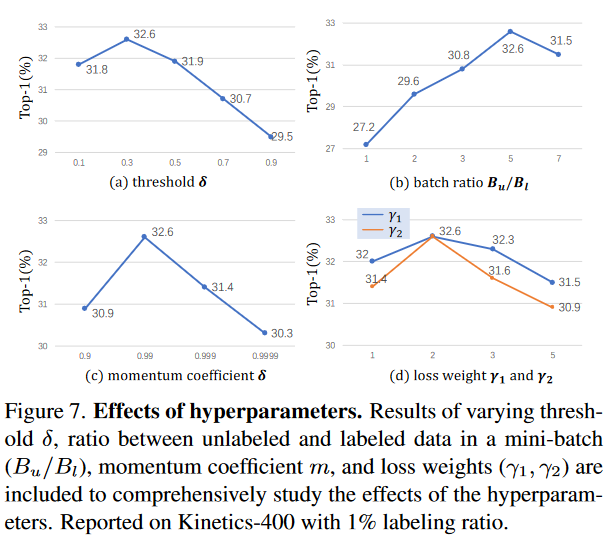
超参数对结果的影响